Machine learning has made content tagging faster, more consistent, and scalable. Instead of spending hours manually assigning labels to digital assets, AI systems use natural language processing (NLP) and large language models (LLMs) to tag content in seconds. This ensures accuracy, improves searchability, and reduces operational effort.
Key Takeaways:
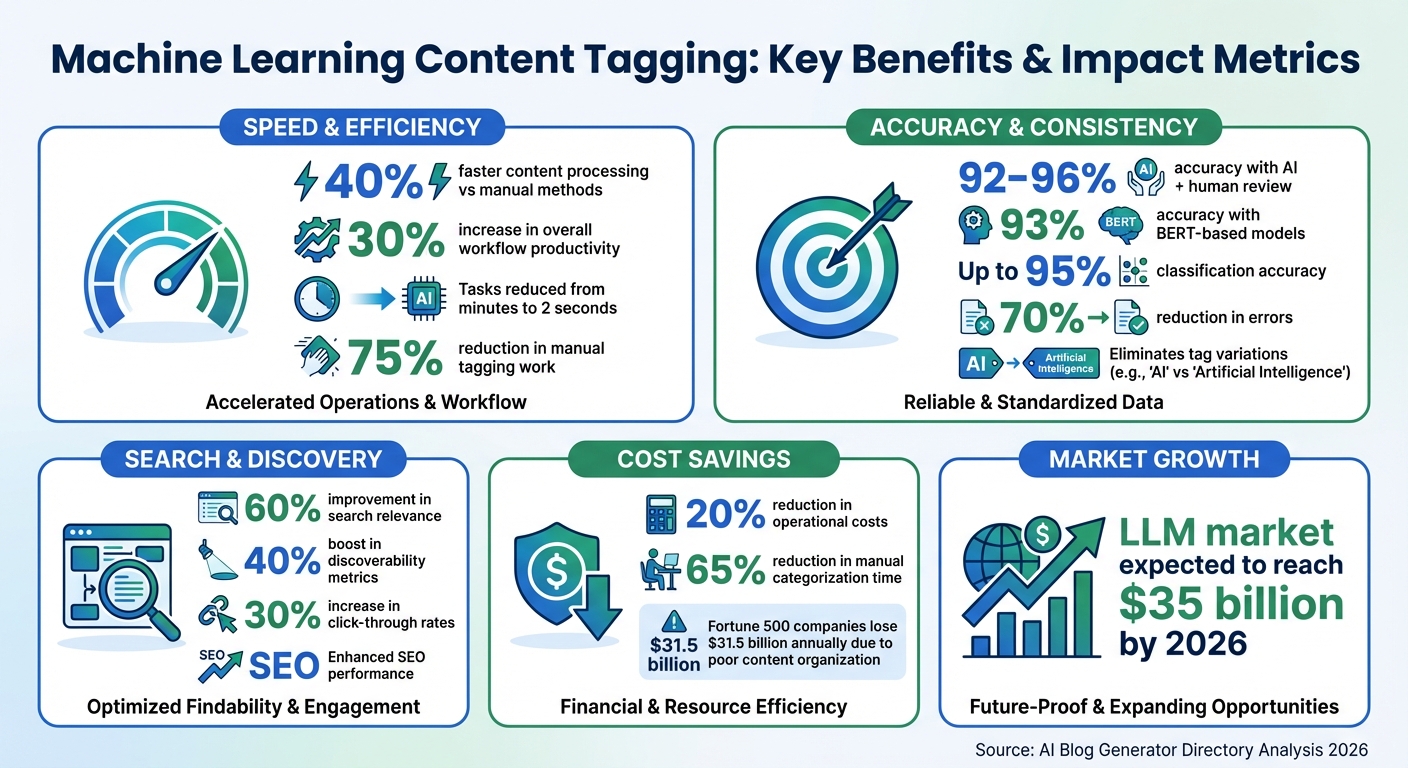
- Speed: AI tags content up to 40% faster than manual methods.
- Consistency: Eliminates variations like "AI" vs. "Artificial Intelligence."
- Improved Search: Boosts search relevance by 60% and SEO performance.
- Cost Savings: Cuts tagging-related costs by 20% and reduces manual work by 75%.
- Scalability: Efficiently handles large content libraries with minimal human input.
How It Works:
- AI analyzes text, identifies key concepts, and applies structured tags.
- Techniques like NLP, semantic analysis, and named entity recognition ensure context-aware tagging.
- LLMs like GPT-4 or Llama 3.1 can work with minimal training, making them adaptable for various industries.
Implementation Steps:
- Define a clear taxonomy with categories and tags.
- Clean and structure your content data.
- Use AI models for tagging, combining them with human review for edge cases.
- Test and refine the system using metrics like precision and recall.
Machine Learning Content Tagging Benefits: Key Statistics and Impact Metrics
How to Use AI to Tag Marketing Content
sbb-itb-a759a2a
Machine Learning Techniques for Content Tagging
Machine learning drives content tagging by analyzing text, identifying key concepts, and assigning structured labels. These methods improve how content is organized, making it easier to find and manage.
Natural Language Processing (NLP)
NLP allows systems to go beyond simple keyword matching and actually understand the content. By analyzing sentence structure and word relationships, it captures the context of text. For instance, BERT-based models, a type of NLP technology, can achieve about 93% accuracy in tagging tasks. When automated tagging is paired with human review, accuracy can climb to between 92% and 96%.
Semantic Analysis and Named Entity Recognition
Named Entity Recognition (NER) focuses on identifying specific elements within text, such as names of people, locations, brands, or products. For example, in an article about Apple's latest product launch in San Francisco, NER would recognize "Apple" as a company and "San Francisco" as a location. It also resolves ambiguities to ensure accuracy.
Semantic analysis takes this a step further by uncovering underlying themes in the content. This method helps maintain consistency by aligning tags with a controlled vocabulary, which prevents an overwhelming number of tags from being generated.
Large Language Models (LLMs)
LLMs like GPT-4 and Llama 3.1 are at the forefront of automated tagging. These models use zero-shot learning, meaning they can categorize content without needing to be trained on your specific data. Simply provide the model with your taxonomy, and it can start analyzing content right away.
A notable example comes from February 2026, when a tech company implemented Meta's Llama 3.1 model with Weaviate 4.1's semantic-aware chunking to tag internal documentation. This initiative achieved a 92% accuracy rate in categorizing documents, improved search relevance by 60%, and cut manual tagging efforts by 75% for their engineering database. The global LLM market is expected to hit $35 billion by 2026.
The most effective systems combine LLMs with semantic validation. As Pascal Tags explains:
The optimal approach combines LLMs with taxonomy constraint: LLM as intelligent suggester + taxonomy as validator + human review for edge cases.
This hybrid strategy ensures that LLMs don’t create an excessive number of unique tags while still allowing for the identification of new and emerging topics. These approaches lay the groundwork for a more efficient tagging process, as explored in the following section.
How to Implement Machine Learning Content Tagging
This section breaks down the steps to effectively use machine learning for content tagging. Let’s dive into the process.
Step 1: Define Your Tag Categories
Start by building a clear and structured taxonomy. Your tag categories should align with the complexity of your content. For instance, if your content focuses on technical topics like cloud infrastructure, broad categories won’t suffice. You’ll need a more detailed structure.
Organize your tags into functional groups like:
- Topic: Techniques and strategies.
- Use Case: Broad applications, such as Marketing Analytics.
- Industry: Sectors like Healthcare or Education.
A hierarchical system works best. Use high-level Concepts for overarching themes, Categories for broader clusters, and Tags for specific descriptors like "CI/CD" or "Azure Pipelines".
Avoid cryptic internal codes (e.g., "ML 201"). Instead, use descriptive labels like "Advanced Machine Learning and AI" to make tags easier for machines to interpret. As Michael Andrews from Kontent.ai puts it:
Tags offer a standard language that can be used across the organization to manage and coordinate its content. Providing the right content by relying on tags depends on getting the tags right.
Before automating, refine your manual tagging process. This ensures you’re not automating flawed systems and helps you spot gaps in your taxonomy.
Step 2: Prepare Your Content Data
Clean and structure your data for better tagging accuracy. Instead of processing entire articles (which can increase costs and complexity), focus on titles and headers (h1, h2 tags), as they often contain the most critical information.
Steps to clean your data:
- Normalize text: Convert everything to lowercase, remove special characters, and eliminate stopwords like "the" or "is" that don’t add value.
- Use regular expressions to strip out unnecessary elements like image paths (.jpg), metadata, or formatting codes that could interfere with analysis.
For training models, use TF-IDF (Term Frequency-Inverse Document Frequency) to highlight keywords that matter most across your content library. Tools like Sklearn’s MultiLabelBinarizer can convert tag sets into formats that machine learning models can process.
Begin with a "ground truth" dataset, which includes content manually tagged by experts. This serves as a reliable benchmark to evaluate your model’s performance.
Step 3: Set Up Your Machine Learning Models
Choose between extractive tagging and predictive tagging based on your needs:
- Extractive tagging: Identifies keywords already present in the text. It’s great for uncovering new topics and doesn’t require training data.
- Predictive tagging: Uses predefined categories and a labeled dataset for more consistent results.
For Large Language Models, include 3-4 examples of correctly tagged content in your prompt (few-shot learning) to guide the model. Lower the temperature parameter to reduce randomness and ensure consistent tags.
To improve accuracy, use a two-step process: first confirm the relevance of a tag (Yes/No), then assign it only if validated. This avoids assigning irrelevant tags.
Step 4: Test and Improve Your Tags
Evaluate your tagging system with metrics like:
- Precision: Ensures you avoid incorrect tags.
- Recall: Ensures you don’t miss relevant tags.
The F1-score, which balances precision and recall, is the standard for optimizing multi-label classification. Fine-tune classification thresholds on a validation set to strike the right balance.
In the initial stages, implement a Human-in-the-Loop (HITL) process. This involves human reviewers verifying uncertain tags before full automation. It’s especially helpful for nuanced areas like industry or use-case classification.
Lastly, use topic taxonomies to automatically assign parent tags. For example, tagging "Machine Learning" could also trigger the broader "Artificial Intelligence" category. This ensures a more comprehensive tagging system.
Benefits of Automated Content Tagging
Easier Content Management
Managing a large content library can feel like trying to organize a chaotic filing cabinet. That’s where machine learning steps in. AI systems can scan through articles, videos, and documents, instantly tagging them with labels like "billing issue" or "product update." This eliminates the need for manual classification, making your content searchable as soon as it’s uploaded.
The real value becomes apparent as your library grows. Automated systems can handle thousands of items - something that would be nearly impossible to manage manually - allowing your team to scale without hiring more staff. Many companies have already seen improved accuracy and reduced manual labor thanks to these tools.
Consistency is another major win. Automation ensures standardized tagging, so you won’t end up with mismatched labels like "finance" and "financial sector". This is especially useful for modular content creation, where tags help you quickly locate and combine elements like headers, images, and calls-to-action into new pages.
All these organizational benefits lead to better search functionality and a more engaging user experience.
Better SEO and Search Results
Automated tagging doesn’t just make organizing content easier - it also makes it easier to find. By creating structured metadata, machine learning helps search engines better understand your content, leading to more effective indexing. In fact, AI-driven categorization has been shown to improve search relevance by 60%.
This technology also enables semantic search, which goes beyond exact keyword matches. For example, a user searching for "woodworking" might also find content on "carpentry", even if that specific term isn’t mentioned. Features like faceted search allow users to filter content by category, topic, or attribute, speeding up the process of finding what they need.
Automated tagging also enhances internal navigation. Taxonomies created through AI can generate links to related articles, improving SEO and keeping visitors on your site longer. Personalized content recommendations, powered by these tags, have increased click-through rates by up to 30%. For instance, in 2026, a global media organization used Hugging Face’s Transformers 5.0 library to categorize multimedia news content, boosting discoverability metrics by 40% across its platforms.
Saves Time and Money
While automated tagging improves organization and SEO, it also delivers measurable savings in both time and money. By eliminating the manual effort of labeling content, businesses can cut operational costs by 20%. This allows teams to shift their focus to creative and strategic tasks.
The speed improvements are just as impressive. Automated systems can process content 40% faster, handling large volumes in seconds. This efficiency can lead to a 30% boost in overall workflow productivity. Plus, AI systems have achieved up to 95% accuracy in content classification, reducing errors and ensuring reliability.
| Metric | Impact of Automation |
|---|---|
| Efficiency | 30% increase |
| Operational Costs | 20% decrease |
| Content Processing Speed | 40% increase |
| Classification Accuracy | Up to 95% |
| Manual Categorization Time | 65% reduction |
Scalability is another huge advantage. Automated tools grow with your business without requiring proportional increases in costs. As David Baldry, Senior Enterprise Solutions Engineer at Contentful, explains:
Content tags shouldn't be considered a nice-to-have luxury that you can add to nudge the search performance of your content - they're a critical content management priority.
For businesses looking to scale efficiently, automated tagging is a game-changer, offering a cost-effective way to manage ever-expanding content libraries.
Best Practices and Common Challenges
Use Clean, Organized Data
The performance of your machine learning model heavily depends on the quality of your training data. Poorly labeled or inconsistent data can slash model accuracy by up to 80%. To avoid this, establish a clear and consistent controlled vocabulary across your platform.
Start with a perfectly accurate seed set, and make sure to deduplicate and standardize your data - whether it’s dates, currencies, or naming conventions - to sharpen the model’s focus. For long-form documents, segment the text into meaningful chunks based on semantics instead of arbitrary character limits. This approach leads to better model accuracy and focus.
Avoid using irrelevant or vague labels that could lead to over-tagging. Stick to a manageable limit of 3 to 5 tags per asset to prevent "tag bloat" and ensure search results remain clear. While manual labeling can consume up to 70% of project resources, investing in clean, well-organized data upfront can save significant time and effort later on.
This groundwork is crucial for smooth integration with your Content Management System (CMS).
Connect with Your Content Management System
Modern tagging solutions typically provide APIs that allow seamless communication between your CMS and the AI engine. These integrations enable real-time tagging of new content, reducing the need for manual input while still allowing for human review.
For instance, in early 2026, a major tech company implemented Meta's Llama 3.1 within a Retrieval-Augmented Generation (RAG) setup to tag internal technical documents. By leveraging Weaviate 4.1's semantic-aware chunking, they achieved a 92% accuracy rate in document categorization, cutting manual tagging efforts by 75% and boosting search relevance by 60%.
For organizations handling sensitive data, local Large Language Models (LLMs) provide a secure integration option, keeping all data within the network. Ensure that tagged metadata is directly visible in the CMS interface to streamline workflows for content editors. Before integrating, audit your existing content to ensure consistency and compatibility with the tagging system. This CMS integration complements earlier machine learning efforts and ensures real-time, reliable tagging.
Add Human Review for Uncertain Results
Even with clean data and CMS integration, human oversight remains critical. No system is flawless, and a human-in-the-loop (HITL) approach can address low-confidence tags flagged by the system. This process not only ensures accuracy but also provides valuable feedback to improve the model over time.
Set relevance thresholds to filter out low-confidence tags, ensuring only the most appropriate labels are applied. As Martin Hinshelwood, Principal Consultant at NKDAgility, points out:
AI systems have agency, but it is limited to tactical optimisation, they can suggest, rank, and cluster, but they cannot own accountability for what gets published or accepted. That's the human's job.
Overly large taxonomies can hurt model performance, so focus on essential categories. Large Language Models may also produce believable but inaccurate tags or inconsistently tag identical content across runs. Employing active learning strategies can cut manual annotation needs by over 60%, making human review more efficient while maintaining high standards of quality.
Conclusion
Key Takeaways
Machine learning has transformed tagging from a manual chore into an automated process, cutting down errors by up to 70% and increasing operational efficiency by as much as 40%. Tasks that used to take several minutes now finish in just two seconds.
This leap in efficiency does more than save time - it ensures consistency across your entire content library. Manual tagging often leads to inconsistencies, but AI applies the same logic uniformly. This consistency enhances SEO, improves internal search results, and powers recommendation engines to deliver the right content exactly when it’s needed. Poor content organization costs Fortune 500 companies an estimated $31.5 billion annually, and automated tagging directly addresses this costly issue.
AI technology continues to evolve. Hybrid models that combine large language models with semantic validation now achieve accuracy rates of 92% to 96%. Active learning techniques further reduce the need for manual annotation by over 60%, freeing up creators to focus on strategy and creative projects instead of repetitive tasks.
However, human oversight remains critical. Automation is powerful, but it can’t replace accountability. As Martin Hinshelwood of NKDAgility points out:
AI systems have agency, but it is limited to tactical optimisation... they cannot own accountability for what gets published or accepted. That's the human's job.
To get the most out of AI tagging, start with clean, well-organized data, use a controlled vocabulary, and integrate human review for uncertain cases. This balance between AI efficiency and human judgment ensures both scalability and quality.
Using the AI Blog Generator Directory
To take full advantage of these AI tagging advancements, the AI Blog Generator Directory (https://aibloggenerators.com) offers a range of tools tailored for content creators. These tools cover SEO optimization, automated keyword research, CMS integration, and text editing, streamlining the entire content creation process.
The directory includes solutions for various needs, from simple web tools for occasional tagging to API-based systems for large-scale automation. Many of these tools offer free tiers - handling up to 500 requests per day - so you can test them before committing to paid enterprise plans. Whether you’re running a small blog or managing a vast content library, the directory helps you find tools for text, images, and videos, leveraging advanced models like Meta’s Llama 3 or OpenAI’s GPT-4.
Start by defining your tagging categories, then explore the directory to find tools that align with your goals and budget. With the right AI tagging solution, you can cut content management time by 30% to 40%, all while delivering the consistency and precision your audience expects.
FAQs
Do I need training data to auto-tag content?
Yes, training data plays a crucial role in auto-tagging systems. For machine learning models, especially those using supervised learning, this data serves as the backbone for assigning accurate and relevant tags. By analyzing training data, the system learns to recognize patterns and associations, enabling it to make informed tagging decisions. Without this foundational step, the model would struggle to deliver precise results.
How do I stop tag bloat and duplicate tags?
To keep your tags organized and prevent duplicates, stick to a controlled vocabulary or a standardized tag list. Regularly review and tidy up your tags to eliminate redundancies. Tools like automated content tagging systems and machine learning algorithms can group similar tags, cut down duplication, and streamline your tagging process. Scheduling periodic audits of your tagging system helps ensure your tags remain relevant and don’t grow out of control.
How can I measure tagging quality over time?
To gauge the quality of tagging, you can rely on metrics like precision, recall, and the F1 score, which collectively measure how accurate and consistent the tagging process is. Beyond these, regularly analyzing user engagement and content retrieval metrics - such as how easily users can locate tagged content - offers a practical way to assess relevance. Manual reviews or audits also play a key role by uncovering errors and offering valuable qualitative feedback. By blending these approaches, you can effectively monitor and refine tagging performance over time.

