Semantic content search is transforming how we find information, focusing on meaning and intent rather than just matching keywords. Whether you're a content creator, developer, or business using the best AI content generator tools, these search solutions help you locate relevant data faster and more accurately. Here's a quick look at the top tools in 2026:
- Firecrawl: Simplifies web data extraction with semantic search and supports large-scale workflows. Free tier available.
- Exa: Combines neural and keyword search for precise results, great for LLM applications. Pay-as-you-go pricing.
- Pinecone: Scalable vector database with serverless architecture, ideal for enterprise needs. Starts at $50/month.
- Meilisearch: Open-source, fast, and affordable. Self-host for free or use managed plans from $30/month.
- Typesense: In-memory search engine blending keyword and semantic search. Free self-hosted or managed plans starting at $7/month.
- Weaviate: Open-source vector database with multi-modal search and managed cloud options. Free sandbox available.
- Qdrant: High-performance vector search with hybrid capabilities and enterprise-ready features. Free cloud tier.
Quick Comparison:
| Tool | Free Tier | Hybrid Search | Scalability Focus | Starting Price |
|---|---|---|---|---|
| Firecrawl | 500 credits | SERP-based extraction | Web crawling at scale | $19/month (Hobby) |
| Exa | $10 credits | Neural + indexing | LLM-optimized retrieval | Pay-as-you-go |
| Pinecone | Starter plan | Vector-focused | Managed cloud | $50/month minimum |
| Meilisearch | Open-source | Full-text + vector | Self-hosted | Free (self-host) |
| Typesense | Open-source | Keyword + vector | Self-hosted | Free (self-host) |
| Weaviate | Sandbox tier | Multi-modal vectors | Distributed architecture | Free sandbox |
| Qdrant | Forever free cloud | Dense + sparse vectors | Enterprise-scale | Free tier |
Each tool offers unique strengths, from large-scale crawling to token-efficient search for AI systems. Consider your specific needs - like scalability, pricing, or hybrid search capabilities - when choosing the best option.
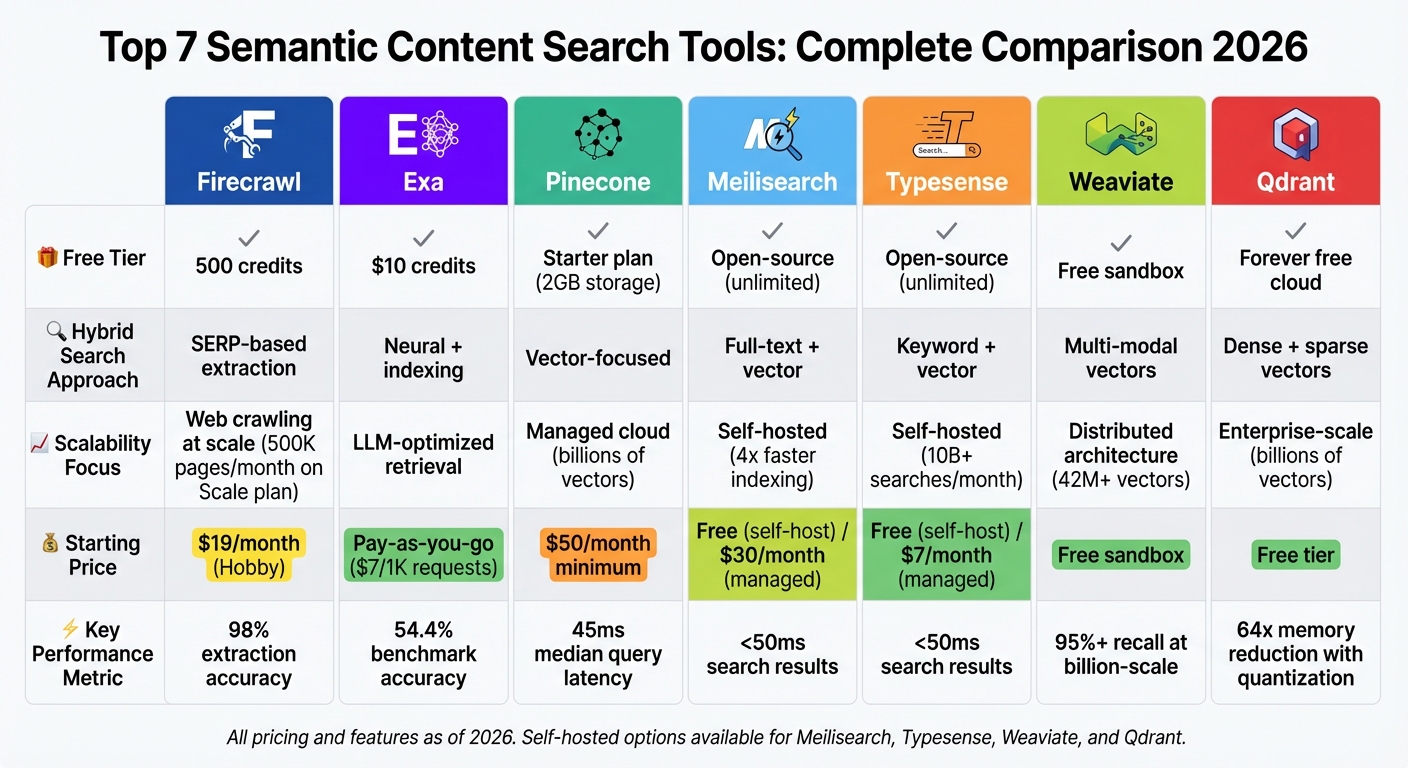
Semantic Content Search Tools Comparison: Features, Pricing, and Scalability
Beyond Keywords: A Hands-on Guide to Modern Semantic Search Techniques
sbb-itb-a759a2a
1. Firecrawl
Firecrawl simplifies a complex five-step process into a single API call, delivering data that's ready for large language models (LLMs). Instead of relying on fragile CSS selectors that can break during layout changes, it uses natural language prompts for extraction. This means you can request specific data types without needing to understand the underlying HTML structure.
The platform’s efficiency is powered by its semantic search capabilities, ensuring accurate and reliable data retrieval.
Semantic Search Capability
Firecrawl boasts an impressive 98% extraction accuracy by leveraging a semantic layer that interprets content based on meaning rather than rigid patterns. Its Fire-Engine technology handles JavaScript rendering and bypasses anti-bot measures, enabling it to access 96% of the web, including protected or JavaScript-heavy pages.
For content creators using advanced AI tools for blog content creation, this translates to effortless data collection without manual effort - the semantic layer automatically identifies and extracts relevant information in context. For AI systems, Firecrawl offers a dedicated endpoint that allows autonomous agents to navigate, click, and interact with web pages, gathering multi-step research data with ease for AI writer tools.
Scalability for Large Datasets
Firecrawl is built to handle large-scale content workflows efficiently. It supports asynchronous crawling, monitored through webhooks and WebSocket connections. The Standard plan allows up to 50 concurrent requests, while the Scale plan processes up to 500,000 pages per month.
Performance benchmarks highlight its speed and reliability. Firecrawl delivers results in under 1 second and maintains a P95 latency of 3.4 seconds across millions of pages. Compared to traditional scraping tools, it is 33% faster and achieves a 40% higher success rate.
Pricing and Availability of Free Tiers
| Plan | Price/Month | Credits | Concurrent Requests |
|---|---|---|---|
| Free | $0 | 500 | 2 |
| Hobby | $16 | 3,000 | 5 |
| Standard | $83 | 100,000 | 50 |
| Scale | $333 | 500,000 | High volume |
The Free tier offers 500 credits, ideal for testing. The Hobby plan, at $16/month, suits smaller projects. The Standard plan provides 100,000 credits and robust concurrency for production needs. For enterprise users, custom plans with unlimited credits and dedicated SLAs are available.
2. Exa
After Firecrawl efficiently extracts data, Exa takes things a step further by refining semantic search through an in-depth analysis of query context. By leveraging neural search, Exa interprets the intent behind a query, making it a go-to tool for complex research tasks where basic keyword matching falls short. Its hybrid search model blends neural understanding with keyword ranking, offering both speed and precision.
Semantic Search Capability
Exa achieves an impressive 54.4% accuracy rate on benchmarks, outperforming competitors like Perplexity and Brave. One standout feature is its "Find Similar" tool, which allows users to input a URL and discover semantically related websites. To streamline results, Exa’s API automatically removes ads, navigation bars, and other HTML clutter, delivering clean, parsed text that’s ready for use in large language models.
The platform’s extensive web index includes over 1 billion people profiles, 70 million company pages, and more than 100 million full research papers. Exa also supports "Long Queries," enabling users to input extended text blocks to find semantically rich content. Its "Highlights" feature extracts key excerpts (recommended around 4,000 characters), reducing LLM token costs by over 50%. When paired with Exa’s hybrid approach, this feature significantly sharpens search accuracy.
"Exa's powerful search capabilities have been instrumental in delivering the high-quality, relevant web content our users need while maintaining our commitment to privacy and user control." - Sarah Sachs, AI Engineering Lead, Notion
Support for Hybrid Search (Semantic + Keyword)
Exa’s hybrid search combines the strengths of semantic understanding with the precision of keyword-based methods, making it a versatile tool for AI tools for content creators. The platform offers multiple search options to suit different needs:
- Instant Search: Results in about 200ms, ideal for real-time use.
- Fast Search: Processes results in roughly 450ms.
- Deep Search: Tailored for complex queries, delivering results within 5 to 60 seconds.
This flexibility allows users to balance speed and depth, depending on their workflow priorities.
Pricing and Availability of Free Tiers
Exa’s pricing structure is flexible, catering to a variety of project sizes. The free tier provides up to 1,000 requests per month, perfect for testing or small-scale use. For larger needs:
- Standard Search: $7 per 1,000 requests (up to 10 results per query).
- Deep Search: $12 per 1,000 requests, designed for more intricate queries.
- Contents Endpoint: $1 per 1,000 pages.
- Answer Feature: $5 per 1,000 requests.
Additionally, startups and educational initiatives can access $1,000 in free credits through special grants.
3. Pinecone
Pinecone builds on the success of hybrid search tools by focusing on scalability and efficient infrastructure for managing massive datasets. Its serverless architecture separates storage, read, and write functions, allowing each to scale independently without manual adjustments. This setup can handle billions of vectors while maintaining a median query latency of just 45ms. By combining Exa's hybrid approach with its own serverless design, Pinecone achieves impressive performance.
Semantic Search Capability
Pinecone uses dense vector embeddings to enable searches based on meaning rather than exact keywords. Integrated inference converts raw text into vectors and reranks results to improve accuracy. To support multi-tenant applications, the platform offers namespace partitioning, which isolates data and supports up to 1.7 million namespaces and 400 global queries per second.
The platform also includes metadata filtering, allowing real-time pre-filtering by categories, dates, or user IDs without sacrificing speed. Joshua Beck, CEO of Melange, highlighted Pinecone's reliability for critical patent searches:
"Our entire search operation relies on Pinecone as the first step in the process. When we evaluated the developer experience and time saved, Pinecone was far and away the clear winner".
Scalability for Large Datasets
Pinecone's serverless design can scale to billions of vectors, with real-time indexing that makes new content searchable instantly - eliminating the delays caused by batch processing. This feature is a game-changer for content teams needing immediate access to newly indexed data. Gong, a revenue intelligence platform, leveraged this capability to manage millions of customizable AI agents. Jacob Eckel, VP and R&D Division Manager at Gong, shared:
"Pinecone serverless isn't just a cost-cutting move for us; it is a strategic shift towards a more efficient, scalable, and resource-effective solution".
For high-throughput demands, dedicated read nodes maintain consistent performance even under heavy query loads. Vanguard's customer support team saw a 12% improvement in response accuracy after switching to Pinecone's hybrid retrieval system, speeding up call resolutions.
Support for Hybrid Search (Semantic + Keyword)
Pinecone combines dense and sparse vectors to support both semantic and exact keyword matching, improving accuracy for AI content optimization workflows. This dual-vector approach ensures systems can capture both intent and precise terms. The platform complies with SOC 2, GDPR, ISO 27001, and HIPAA standards, making it suitable for teams working in regulated industries. Additionally, its Bring Your Own Cloud (BYOC) feature, now in public preview, allows organizations to run Pinecone within their own AWS, GCP, or Azure accounts for added security. These features make Pinecone a versatile choice for both small-scale tests and large enterprise deployments.
Pricing and Availability of Free Tiers
Pinecone offers a free Starter tier with no credit card required, providing up to 2GB of storage, 2 million write units, and 1 million read units. The Standard plan starts at $50 per month and scales based on usage, while the Enterprise plan begins at $500 per month, offering advanced security features and dedicated support.
4. Meilisearch
Meilisearch stands out as a fast and cost-efficient AI tool for content search, delivering results in under 50 milliseconds. Unlike tools that depend on expensive large language model (LLM) calls, Meilisearch uses embedding models to transform text into numerical vectors. This approach ensures both speed and affordability while maintaining the ability to understand conceptual meaning. It also handles embedding generation, batching, and caching automatically for providers like OpenAI, Hugging Face, and Cohere.
Semantic Search Capability
Meilisearch uses embedding models and Document Templates with Liquid syntax to create context-aware vectors, focusing on the most relevant information. Features like "Similar Documents" help users find related content effortlessly, while multi-modal search extends functionality to images and audio.
In March 2024, Bookshop.org transitioned its six-million-book inventory to Meilisearch. The result? Their search-to-purchase conversion rate jumped from 14% to 20%, translating into a 43% increase in sales driven by search. CEO Andy Hunter shared:
"With Meilisearch, we achieved a 43% improvement in purchase conversion compared to our previous search engine. Now, 1 out of 5 customers easily find and purchase the book they were looking for".
Scalability for Large Datasets
Meilisearch is designed to handle massive datasets efficiently, using DiskANN (disk-based approximate nearest neighbors) and memory-mapped storage to minimize RAM usage. It supports horizontal scaling through sharding and replication, and Meilisearch Cloud offers features like autoscale disk and a 99.999% uptime SLA. For instance, HitPay, a payment platform, improved its search API speed by 50%, enabling sales assistants to quickly locate products across various physical and online locations.
The platform's next-generation indexer delivers updates 4x faster. Additionally, the "Index Swap" feature allows for large-scale data updates or schema changes without causing any downtime. This focus on scalability also extends to its hybrid search capabilities.
Support for Hybrid Search (Semantic + Keyword)
Meilisearch blends full-text keyword matching with semantic search through the semanticRatio parameter, which balances precision and conceptual relevance. The default setting of 0.5 works well for most cases, prioritizing keyword matches for specific queries like SKUs and semantic matches for broader, descriptive searches. This dual approach ensures flexibility for diverse search needs, offering both speed and depth. Quentin de Quelen, Co-founder & CEO, highlighted the platform’s mission:
"Meilisearch's hybrid search will democratize advanced search technology, focusing on simplicity and open-source customizability".
Pricing and Availability of Free Tiers
Meilisearch offers a range of pricing options, starting with a free-to-self-host open-source version available via Docker and other platforms. For those seeking managed solutions, Meilisearch Cloud provides a 14-day free trial - no credit card required. Paid plans begin at $30 per month for the Build Plan (up to 100,000 documents and 50,000 searches) and $300 per month for the Pro Plan (up to 1 million documents and 250,000 searches).
5. Typesense
Typesense stands out with its in-memory architecture, designed for ultra-fast query performance. Built in C++, it delivers search results in under 50 milliseconds, even at scale. With over 20 million Docker pulls and 24,000 GitHub stars, it handles more than 10 billion searches monthly through Typesense Cloud. However, its reliance on an in-memory design means the entire index must fit in RAM (e.g., a 100GB index requires 100GB of RAM), making careful RAM planning essential.
Semantic Search Capability
Typesense supports semantic search using integrated AI content writing tools and machine learning models like S-BERT, E-5, GTE, and MPNET, or by connecting to external APIs such as OpenAI, Google PaLM, and Vertex AI. It allows users to define an auto-embedding field in collections, automatically generating and storing vector embeddings during data ingestion. The platform also includes retrieval-augmented generation (RAG) for conversational search, offering full-sentence responses based on indexed data. For large-scale deployments, GPU acceleration can significantly speed up embedding generation, reducing processing time from hours to minutes.
Scalability for Large Datasets
Typesense ensures high availability through Raft-based clustering, enabling distributed setups to remain operational even during hardware failures. Typesense Cloud provides managed clusters with hourly resource-based billing, allowing users to scale RAM and CPU as needed. The platform can cut setup time by up to 75% compared to traditional search infrastructures, though organizations must allocate enough RAM to sustain performance. Additionally, it supports geo-distributed caching, bringing data closer to users in different regions to minimize latency.
Support for Hybrid Search (Semantic + Keyword)
Typesense seamlessly integrates keyword and semantic search in a single query by allowing both text and embedding fields in its query parameters. For better ranking accuracy, users can enable rerank_hybrid_matches: true, which combines keyword match scores with vector distance scores. This ensures documents identified through keyword searches are also evaluated for semantic relevance. Parameters like distance_threshold and k can further refine results, limiting searches to the nearest neighbors and improving pagination. As one review highlights:
"Typesense delivers what Elasticsearch promises but without the operational headache" - AI:PRODUCTIVITY
Pricing and Availability of Free Tiers
Typesense offers a free, open-source version for self-hosting, with all features included. Managed solutions via Typesense Cloud start at $7 per month for the Small plan (0.5 GB RAM, shared vCPU) and $50 per month for the Medium plan (4 GB RAM, dedicated vCPU with a high availability option). Unlike platforms that charge per search operation, Typesense uses resource-based pricing (RAM, CPU, and bandwidth), which can be more cost-efficient for large-scale use. This pricing model, combined with its hybrid search capabilities and speed, makes Typesense a strong contender in the search engine space.
6. Weaviate

Weaviate is an open-source vector database that has gained significant traction with over 20 million downloads and a community of 50,000+ AI builders. By using vector embeddings, it indexes data based on conceptual meaning rather than exact keyword matches, making large-scale content discovery more efficient. In real-world applications, Weaviate has handled 42 million vectors, with some users reporting up to 90% faster search speeds for customer service tasks.
Semantic Search Capability
Weaviate stands out for its advanced semantic search capabilities, which are particularly useful for content creators aiming for precise data discovery. It uses the HNSW (Hierarchical Navigable Small World) indexing algorithm to create a vector graph that quickly identifies similar items, achieving over 95% recall even at a billion-scale dataset. The platform supports multi-modal search, allowing users to search across text, images, audio, and video. It also integrates seamlessly with major model providers like OpenAI, Cohere, Google, and AWS for generating embeddings. Moreover, Retrieval Augmented Generation (RAG) enhances search results by converting them into natural language responses through integration with generative AI models. This synergy is often found in advanced AI text generation tools that combine retrieval with creative output.
Scalability for Large Datasets
Weaviate is designed to handle growing datasets with ease, offering both horizontal and vertical scaling options. It can pre-filter results based on specific criteria to improve relevance. For teams looking to avoid the complexity of managing infrastructure, Weaviate Cloud provides automated scaling and managed services. As Kerry Chang, Head of Product Engineering, explained:
"Accuracy - how good the answer is - is the first thing we want to optimize for. That's how we found Weaviate".
Support for Hybrid Search (Semantic + Keyword)
Weaviate combines vector search with BM25 keyword search, running both simultaneously and merging the results. Users can fine-tune the balance between the two using an alpha parameter - setting it to 0 for pure keyword search, 1 for pure vector search, or 0.5 for an even mix. For specialized fields like legal or medical content, the platform also supports reranking using cross-encoder models from Cohere or Hugging Face to improve accuracy.
Pricing and Availability of Free Tiers
Weaviate provides flexibility with its pricing options. The open-source version is free to self-host using Docker or Kubernetes and includes all core features. For those who prefer a managed solution, Weaviate Cloud offers a free sandbox instance for testing and development. It also provides shared cloud infrastructure for production workloads and dedicated instances for enterprise users. Enterprise features include robust security measures like RBAC, SOC 2, and HIPAA compliance, catering to organizations with strict regulatory requirements.
With its versatile capabilities and scalable infrastructure, Weaviate sets the stage for the next tool, Qdrant.
7. Qdrant
Qdrant is a vector search engine designed for large-scale semantic search, built using Rust for performance and reliability. With over 25,000 stars on GitHub and a growing community of more than 60,000 members, it has become a popular choice for managing extensive datasets. Using its custom storage engine, Gridstore, and SIMD optimizations, Qdrant delivers fast and scalable vector search without relying on external frameworks. It builds on the strengths of earlier tools while introducing new optimizations to streamline semantic search.
Semantic Search Capability
Qdrant's hybrid search approach combines dense vectors for semantic understanding with sparse vectors (like BM25 and SPLADE++) for precise keyword matching. This ensures results that balance contextual meaning with exact term retrieval. The platform also supports multivector functionality, allowing users to store various embeddings - such as text and image - in a single collection.
Qdrant employs a one-stage filtering method, applying metadata filters during the HNSW traversal process. Its Query API, launched in version 1.10, enables server-side fusion of multiple search methods through Reciprocal Rank Fusion (RRF), eliminating the need for external tools to merge results. Additionally, Qdrant Cloud can generate text and image embeddings directly using built-in models like sentence-transformers, removing the hassle of setting up separate embedding pipelines.
Scalability for Large Datasets
Qdrant is built to handle enterprise-scale content search with features like auto-sharding and multi-node deployment. These capabilities ensure low latency and high throughput, even when managing billions of vectors. Real-world use cases showcase its performance:
- Lyzr: Achieved a 90% reduction in latency and boosted throughput by 150% for its AI agents.
- Dust: Scaled vector search across more than 5,000 data sources.
- AI Trip Planner: Utilized Qdrant to process billions of reviews and images, leading to a reported 2–3× revenue increase.
To optimize memory usage, Qdrant employs advanced quantization techniques, such as scalar, binary, and asymmetric options, which can reduce memory needs by up to 64×. For text-heavy applications, sparse vectors offer significant savings - requiring only 1.12 GB of memory per 1 million documents compared to 12.288 GB for dense OpenAI embeddings. Users can further enhance performance by creating payload indexes for integer or keyword fields before uploading large datasets. These optimizations result in faster searches and smoother data retrieval for users of content writing tools for bloggers.
Support for Hybrid Search (Semantic + Keyword)
Qdrant takes hybrid search to the next level by combining dense and sparse vector scores using Reciprocal Rank Fusion (RRF) for unified ranking. Multi-stage retrieval options allow for additional refinement, such as re-ranking results with late interaction models like ColBERT. Sparse vectors excel at exact term matching, making them ideal for rare keywords or specific queries like "64.2 inch console table", while dense vectors capture broader context, including intent and multilingual nuances. Benchmarks consistently show hybrid search outperforming single-method approaches. For example, SPLADE (sparse) achieved an MRR@10 of 0.322, while DistilSPLADE-max reached 0.368.
"Hybrid search is not extra complexity, it's what actually works in production".
Pricing and Availability of Free Tiers
Qdrant offers a "forever free" cloud tier, perfect for prototyping semantic search, with no credit card required. The open-source version is also free to self-host, providing access to all core features. For production environments, Qdrant Cloud delivers fully managed deployments on AWS, GCP, or Azure, complete with auto-sharding and high availability. Enterprise options include Hybrid Cloud (Bring Your Own Kubernetes) and Private Cloud (air-gapped deployments) for organizations with strict compliance needs. The platform is SOC2 and HIPAA compliant, making it a solid choice for industries like healthcare and finance.
Feature Comparison
This section breaks down key differences across the seven platforms to help you choose the right tool for your needs. Your decision will likely depend on factors like budget, technical setup, and specific workflow requirements. The platforms vary in pricing structures, hybrid search approaches, and scalability options. Below, you'll find a comparison table and summary to clarify these distinctions.
When it comes to pricing, tools generally fall into three categories:
- Self-hosted solutions: Meilisearch and Typesense offer free, open-source versions, making them budget-friendly options alongside other free AI writing tools.
- Pay-as-you-go models: These provide flexibility for startups. For instance, Exa includes $10 in free credits, and Firecrawl offers a free tier for testing.
- Subscription-based plans: Firecrawl's plans start at $19/month for the Hobby tier and go up to $399/month for Growth. Pinecone, on the other hand, requires a $50/month minimum for production-grade features.
Hybrid search methods also differ significantly:
- Meilisearch combines full-text and vector search with typo tolerance, delivering sub-50ms latency for diverse query types.
- Typesense integrates keyword and vector search, supporting both built-in machine learning models and external APIs like OpenAI or PaLM.
- Exa employs a neural-plus-indexing system tailored for LLMs, achieving 94% search accuracy with sub-200ms latency and up to 10× token reduction.
- Firecrawl focuses on a SERP-based approach for live web searches, achieving a 77.2% coverage success rate with automated content extraction.
Hybrid search, which blends semantic and keyword matching, plays a crucial role in enabling efficient content discovery.
| Tool | Free Tier | Hybrid Search | Scalability Focus | Starting Price |
|---|---|---|---|---|
| Firecrawl | 500 credits | SERP-based extraction | Web crawling at scale | $19/mo (Hobby) |
| Exa | $10 credits | Neural + indexing | LLM-optimized retrieval | Pay-as-you-go |
| Pinecone | Starter plan | Vector-focused | Managed cloud | $50/mo minimum |
| Meilisearch | Open-source | Full-text + vector | Self-hosted | Free (self-host) |
| Typesense | Open-source | Keyword + vector | Self-hosted | Free (self-host) |
| Weaviate | Sandbox tier | Multi-modal vectors | Distributed architecture | Free sandbox |
| Qdrant | Forever free cloud | Dense + sparse vectors | Enterprise-scale | Free tier |
Scalability is another critical factor. Managed cloud services like Pinecone, Qdrant, and Weaviate offer features like auto-sharding and multi-node setups to handle billions of vectors. In contrast, Meilisearch and Typesense provide the flexibility of open-source solutions, allowing users to scale infrastructure independently and avoid vendor lock-in. Exa takes a different approach, focusing on token efficiency rather than sheer volume, making it ideal for AI-driven applications where API costs are a concern.
These comparisons highlight how each tool's specific strengths align with modern content creation workflows. For developers, integrating AI content generation APIs into existing systems can further streamline these processes.
Conclusion
Semantic search tools are changing the way content creators interact with information. Instead of spending hours digging through files or relying on manual tagging, these platforms understand both intent and context. This means you can search as naturally as asking a colleague for help. The result? Less time wasted on administrative tasks and more time focused on creative work. These tools simplify workflows and make the entire process smoother.
The numbers back this up: AI-powered tools can cut content production time by 60%–80% and improve asset recall by 40%. This means faster discovery, better recommendations, and seamless integration with tools like Adobe Premiere or your current CMS.
When choosing the right platform, it’s all about identifying your specific challenges. For instance, video editors might need tools with visual analysis, while developers creating AI agents might focus on platforms with strong vector database capabilities. If budget is a concern, open-source solutions could be a better fit than managed services. The comparison table in the previous section outlines trade-offs like pricing, hybrid search methods, and scalability. By evaluating these factors in the context of your workflow, you’ll find the tool that best suits your needs.
Hands-on testing is key here. Most platforms offer free tiers or trials - like Meilisearch’s 14-day trial or Qdrant’s free cloud cluster. Take advantage of these to see how well each tool fits into your workflow. As Robin Da Silva, Founder of Nest Content, wisely points out:
"A tool you cannot integrate into how you already work is a tool you will stop using within a month"
Start with your main use case, experiment with a few platforms, and refine your approach as you go. The right semantic search tool shouldn’t feel like learning complicated new software - it should feel like adding a smart assistant that understands exactly what you need.
FAQs
What’s the difference between semantic search and keyword search?
Semantic search aims to grasp the meaning and context behind a query. It goes beyond just the words typed, focusing on user intent and the connections between different entities. On the other hand, keyword search relies on matching exact terms or phrases, which often overlooks related ideas or synonyms. This difference makes semantic search better at providing relevant results, even when the keywords don’t match perfectly. By using advancements in natural language processing, it enhances how content is discovered and understood.
When should I use hybrid search instead of pure vector search?
Hybrid search is ideal when you need to mix semantic understanding with metadata filtering or attribute-based search to boost both relevance and accuracy. This approach shines in scenarios like e-commerce, where users often combine broad or unclear search queries with specific filters to narrow down their results effectively.
Which tool is best for my use case: web crawling, a vector database, or an in-app search engine?
The right tool hinges on what you're trying to achieve:
- Web crawling tools are ideal for gathering and organizing massive web data sets.
- A vector database works well for semantic searches, helping to interpret and relate content meaningfully.
- An in-app search engine ensures quick, context-sensitive search results directly within your application.
Each tool serves a distinct purpose, so align your choice with your specific objectives.

