StyleGAN is an advanced AI model developed by NVIDIA in 2018 for creating highly detailed and customizable images. Unlike earlier GANs, which often produced unpredictable results when tweaking image features, StyleGAN introduced a more controlled approach to image generation. Its key innovations include:
- Disentangled Latent Space (W): Allows precise adjustments to individual image attributes without affecting others.
- Adaptive Instance Normalization (AdaIN): Refines features at each layer, enabling detailed control over styles and textures.
- Progressive Growing: Builds images step-by-step, starting from low resolution and adding detail as layers progress.
- Path Length Regularization: Ensures smooth transitions when changing image styles, improving consistency and realism.
These features make StyleGAN a powerful tool for applications like digital art, gaming, and text-to-image generation and AI text generation tools. It’s widely used for creating virtual characters, abstract art, and even hyperrealistic portraits. Later versions, such as StyleGAN2 and StyleGAN3, introduced further improvements, addressing artifacts and enabling more natural motion in textures.
For artists and developers, StyleGAN offers a practical way to generate high-quality visuals with fine control over image details, from broad compositions to intricate textures.
StyleGAN2: Near-Perfect Human Face Synthesis...and More
sbb-itb-a759a2a
How StyleGAN Architecture Works
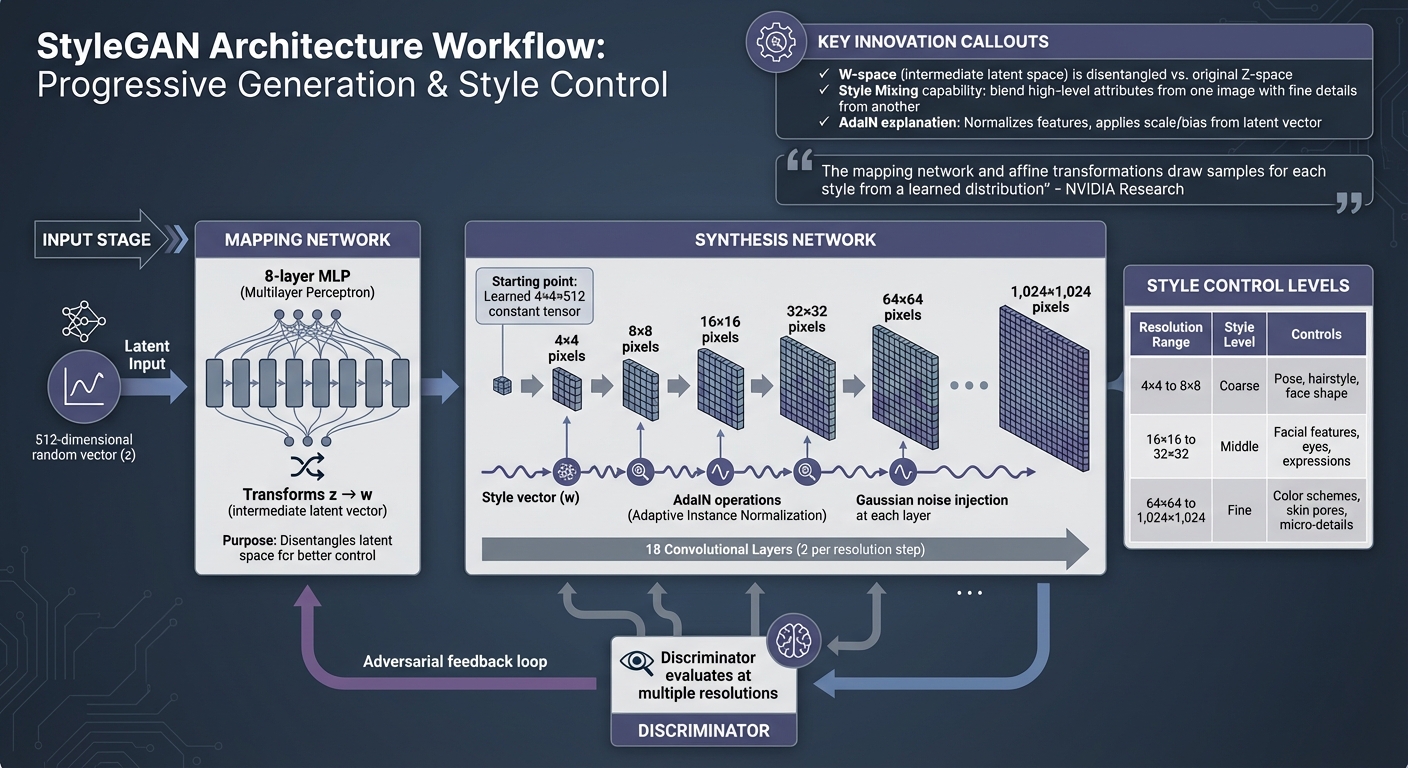
StyleGAN Architecture: From Input to High-Resolution Image Generation
StyleGAN operates on an adversarial framework where the Generator creates images, and the Discriminator evaluates them. This setup sets the stage for StyleGAN's innovative approach to controlling image synthesis with precision.
At its core, StyleGAN's Generator is divided into two parts: the Mapping Network and the Synthesis Network. The Mapping Network, an 8-layer multilayer perceptron, transforms a 512-dimensional input vector (z) into an intermediate latent vector (w). This transformation effectively "unwraps" the latent space, allowing for better control over individual image attributes.
Instead of starting with a random input vector like traditional generators, the Synthesis Network begins with a learned 4×4×512 constant tensor. The latent vector w then fine-tunes the style at each resolution level as the image progresses from 4×4 to a detailed 1,024×1,024 pixels.
Generator and Discriminator Components
Both the Generator and Discriminator grow progressively, moving from low to high resolutions. The Synthesis Network comprises 18 convolutional layers, with two layers dedicated to each resolution step - from 4×4 to 1,024×1,024. This progression allows the network to first capture broad, coarse features and then refine the image into intricate details.
The Discriminator follows a similar approach, evaluating images at multiple resolution levels. As NVIDIA researchers describe, "We can view the mapping network and affine transformations as a way to draw samples for each style from a learned distribution, and the synthesis network as a way to generate a novel image based on a collection of styles." This structure enables precise control over various image attributes, making StyleGAN particularly powerful.
Mapping Network and Latent Space
The original latent space (Z) uses a fixed distribution, which often results in entangled features - where altering one attribute unintentionally affects others. StyleGAN addresses this by introducing the intermediate latent space (W), created by the 8-layer Mapping Network. This space provides a more disentangled and linear representation, making it easier to control individual features.
This disentanglement also supports style mixing, where high-level attributes from one image (e.g., pose or hairstyle) can be blended with fine details from another (e.g., skin texture or colors).
| Style Level | Resolution Range | Controlled Attributes |
|---|---|---|
| Coarse | 4×4 to 8×8 | Pose, general hairstyle, face shape |
| Middle | 16×16 to 32×32 | Facial features, eyes, expressions |
| Fine | 64×64 to 1,024×1,024 | Color schemes, skin pores, micro-details |
Adaptive Instance Normalization (AdaIN)
Adaptive Instance Normalization (AdaIN) plays a key role in refining image features. It takes the intermediate latent vector w and translates it into precise style adjustments. After each convolution, AdaIN normalizes the feature map to have a mean of zero and unit variance. It then applies a scale and bias derived from the latent vector, ensuring that style adjustments are specific to each resolution.
As researcher Nikolas Adaloglou explains, "Previous statistics/styles are discarded in the next AdaIN layer. Thus, each style controls only one convolution before being overridden by the next AdaIN operation." Additionally, Gaussian noise is injected at each layer to introduce subtle variations, enhancing realism without disrupting the overall style or structure of the image.
This combination of AdaIN and Gaussian noise ensures that StyleGAN can produce highly detailed and realistic images, all while maintaining precise control over individual attributes.
Core Techniques in StyleGAN
StyleGAN uses advanced methods to generate stunning, high-resolution images. Two standout techniques are progressive growing and path length regularization, both of which tackle key challenges in training generative models effectively.
Progressive Growing
Progressive growing changes how StyleGAN builds images. Instead of starting with a massive 1,024×1,024-pixel canvas, the model begins with a small 4×4-pixel image and gradually increases the resolution by adding layers. This step-by-step approach allows the network to first focus on the overall structure - like the shape of a head or its pose - before perfecting finer details, such as skin texture or individual hair strands.
"The key idea is to grow both the generator and discriminator progressively: starting from a low resolution, we add new layers that model increasingly fine details as training progresses." - Tero Karras, Lead Researcher, NVIDIA
This method offers practical advantages. For example, studies show that progressive growing can speed up training by as much as 5.4 times. It also helps stabilize the process by preventing the discriminator (a key part of the model) from overpowering the generator too early, which could lead to vanishing gradients or even a complete training breakdown.
To ensure smooth transitions, new layers are introduced gradually. This avoids disrupting features already learned by the model. With progressive growing setting the stage, path length regularization takes consistency to the next level.
Path Length Regularization
After the model refines its output through progressive growing, path length regularization ensures smooth and predictable changes in the generated images. Introduced in StyleGAN2, this technique is all about maintaining consistency in the latent space. Essentially, small adjustments in the latent code should result in equally small and controlled changes in the output image. Without this, the model might behave unpredictably - one tiny tweak could result in either minimal or dramatic changes, creating instability.
Path length regularization works by measuring how sensitive the output image is to changes in the latent code and penalizing any inconsistencies. This eliminates visual glitches, such as the droplet-like artifacts that appeared in the original StyleGAN.
For creators, this means smoother style transitions and the ability to reverse-engineer real images into the latent space for detailed editing. To keep things efficient, the technique is applied every 16 training steps. The effectiveness of path length regularization is often measured using the Perceptual Path Length (PPL) metric, which aligns closely with human evaluations of image quality.
StyleGAN Applications in Artistic Content Creation
StyleGAN has transitioned from a research tool into a go-to resource for creatives. Artists, game developers, and content creators are using it to produce a variety of digital assets - from stock photos and advertising visuals to abstract art and game characters. Let’s dive into how it’s reshaping art, gaming, and text-driven image creation.
Art and Design
StyleGAN empowers artists with feature disentanglement, which means they can tweak specific attributes like texture or pose without altering the entire image. This is perfect for creating customizable advertising visuals and diverse digital media content.
Projects like Generated Photos and MachineRay highlight its potential. For example, in September 2019, Generated Photos released 100,000 AI-generated headshots for free, all featuring consistent lighting and angles. Meanwhile, in August 2020, MachineRay trained StyleGAN2 on 850 public domain paintings from the early 20th century - including works by Mondrian and Kandinsky - to create unique compositions inspired by historical abstract art.
Style mixing is another game changer. It lets designers blend latent vectors, combining structural features from one image with fine details from another. Additionally, transfer learning allows artists to fine-tune pre-trained models on smaller, specialized datasets, opening up even more creative possibilities.
Gaming and Virtual Worlds
StyleGAN is also revolutionizing gaming and virtual environments by streamlining asset creation. It’s used to generate unique NPCs (non-player characters) and environmental assets with intricate details like skin pores and wrinkles, making them look more lifelike instead of repetitive.
A major leap came with StyleGAN 3, which solved the issue of texture sticking - where details like hair or wrinkles stayed fixed during motion. By using alias-free generation, textures now move naturally with objects, a critical improvement for interactive applications. Training a 1,024×1,024-pixel StyleGAN 3 model costs around $2,391 on an 8×V100 server.
"StyleGAN 3 generates state of the art results for un-aligned datasets and looks much more natural in motion" – Justin Pinkney, Lambda
Developers can also manipulate styles at different levels: coarse (pose and face shape), middle (facial features), and fine (color schemes). This level of control speeds up the creation of immersive virtual worlds.
Text-to-Image Tools
StyleGAN-T takes things further by using text prompts to generate visuals. Released in early 2023, it simplifies the creative process by allowing visuals to be generated directly from natural language prompts. This makes it easier for creators to iterate on ideas and streamline their workflows.
For bloggers and content creators, tools like the AI Blog Generator Directory offer curated AI writing and text-to-image tools, making it easier than ever to integrate AI-generated visuals into their projects.
Conclusion
StyleGAN has reshaped the landscape of AI-generated art. Thanks to its disentangled latent space, known as W-space, and its 8-layer mapping network, it has transformed GANs from unpredictable systems into tools that allow for precise adjustments.
Over time, newer versions have built on this foundation. StyleGAN2 addressed issues like blob-like artifacts, while StyleGAN3, released by Nvidia on June 23, 2021, introduced an alias-free design that allows textures to move naturally with surfaces, making it ideal for video and interactive applications.
The scope of StyleGAN has also broadened significantly. StyleGAN-XL now works with diverse datasets like ImageNet, and StyleGAN-T incorporates text-to-image functionality, offering much faster inference speeds compared to diffusion models. These advancements push StyleGAN beyond its original focus on portrait generation, opening doors to a variety of artistic and practical uses. For creators looking to incorporate AI visuals into their projects, resources like the AI Blog Generator Directory offer curated tools to streamline the process.
While challenges such as computational demands and ethical concerns persist, features like task-specific fine-tuning and interactive editing ensure that StyleGAN remains a powerful tool for digital art, gaming asset creation, and synthetic training data. These developments firmly establish StyleGAN as a key player in AI-driven creative workflows.
FAQs
What can I control in W-space that I can’t in Z-space?
In W-space, you have more direct control over the style and appearance of generated images. This includes attributes like textures and specific features, which can be adjusted using style vectors. On the other hand, Z-space offers less flexibility, as it relies on latent codes that influence the output in a more indirect way.
How does style mixing change coarse vs fine details?
Style mixing changes coarse details by affecting the large-scale elements of an image, such as its overall structure or layout. Meanwhile, fine details - like texture and lighting - are tweaked on a smaller scale, enabling more subtle and precise changes to the image's look.
What hardware is required to train or fine-tune StyleGAN?
If you're planning to train or fine-tune StyleGAN, you'll need a high-performance GPU, ideally an NVIDIA model, along with CUDA and cuDNN installed. Training deep GAN models demands significant computational power, often requiring either multiple GPUs or access to high-end servers. Make sure your hardware setup matches these requirements to achieve the best results.


